The source of the atomicity problem is thread switching, and the operating system's thread switching relies on CPU interrupts, so prohibiting CPU interrupts can disable thread switching.
In the early single-core CPU era, this solution is indeed feasible, but it is not suitable for multi-core scenarios. Take a 32-bit CPU to write a long variable as an example. A long variable is 64-bit. A write operation performed on a 32-bit CPU will be split into two write operations.
In a single-core CPU scenario, only one thread executes at a time, disabling CPU interrupts, meaning that the operating system does not reschedule threads, that is, thread switching is disabled, and threads that obtain CPU usage rights can execute without interruption. The second write operation must be: either all are executed, or none are executed, and are atomic.
However, in a multi-core scenario, at the same time, there may be two threads executing at the same time, one thread executing on CPU-1 and one thread executing on CPU-2. At this time, the CPU interrupt is disabled, and only the threads on the CPU can be guaranteed Continuous execution does not guarantee that only one thread executes at a time. If these two threads write a long variable with a high 32 bits at the same time, there may be weird bugs mentioned at the beginning.
The condition of "only one thread executing at a time" is very important and we call it mutually exclusive. If we can guarantee that modifications to shared variables are mutually exclusive, then atomicity can be guaranteed for both single-core and multi-core CPUs.
Simple lock model
A section of code that requires mutually exclusive execution is called a critical section. Before the thread enters the critical section, it first attempts to lock lock (). If it succeeds, it enters the critical section. At this time, the thread is said to hold the lock. If the lock is not successful, it waits until the thread holding the lock unlocks. After executing the code of the critical section, the thread executes unlock ().
Improved lock model
In the real world, there is a corresponding relationship between the lock and the resources to be protected by the lock. In the concurrent programming world, locks and resources should also have this relationship

First, we need to mark the resources to be protected in the critical section. As shown in the figure, an element is added to the critical section: protected resource R; second, we must protect the resource R by creating a lock LR for it; finally, For this lock LR, we also need to add a lock operation and an unlock operation when entering and exiting the critical section. In addition, I made a special association between the lock LR and the protected resource. This association is very important. Many concurrent bugs occur because they are ignored, and then something similar to locking their own doors to protect their assets appears. Such bugs are very difficult to diagnose, because we believe that we have locked them properly.
Locking technology provided by the Java language: synchronized
Locks are a common technical solution. The synchronized keyword provided by the Java language is an implementation of locks. The synchronized keyword can be used to decorate methods or code blocks. Its usage examples are basically as follows:
classX {
// 修饰非静态方法
synchronized void foo(){
// 临界区
}
// 修饰静态方法
synchronized static void bar(){
// 临界区
}
// 修饰代码块
Object obj = new Object();
void baz(){
synchronized(obj) {
// 临界区
}
}
}
After reading it, you may feel a bit strange. This model is a bit out of place with the model we mentioned above. Where are the lock () and unlock ()? In fact, these two operations are available, but these two operations are added silently by Java. The Java compiler automatically adds lock () and unlock () before and after the synchronized method or code block. The advantage of this is that lock () and unlock () must be paired. After all, forgetting to unlock unlock () is a fatal bug.
Where are the objects locked by lock () and unlock () in synchronized? In the above code, we saw that when only the code block was modified, an obj object was locked. What was locked when the method was modified? This is also an implicit rule of Java:
- When decorating a static method, the Class object of the current class is locked, in the above example it is Class X;
- When decorating a non-static method, the current instance object this is locked.
For the above example, the synchronized static method is equivalent to:
classX{
// 修饰静态方法
synchronized(X.class) staticvoidbar(){
// 临界区
}
}
Decorating a non-static method is equivalent to:
classX{
// 修饰非静态方法
synchronized(this) voidfoo(){
// 临界区
}
}
Solving count += 1 with synchronized
I believe you must remember the concurrency problem of count + = 1 mentioned in our previous article. Now we can try to use synchronized to try a little bit. The code is shown below. The SafeCalc class has two methods: one is the get () method to get the value of value; the other is the addOne () method to add 1 to the value, and the addOne () method is decorated with synchronized. So are there any concurrency issues with the two methods we use?
class SafeCalc{
long value = 0L;
long get(){
return value;
}
synchronized void addOne(){
value += 1;
}
}
Let's first take a look at the addOne () method. First of all, we can be sure that after being modified by synchronization, whether it is a single-core CPU or a multi-core CPU, only one thread can execute the addOne () method, so it must be able to guarantee atomic operations. Is there any visibility? What's the problem? To answer this question, it is necessary to revisit the rules of locking in the management process mentioned in the previous article.
The lock rule in the management process: unlocking a lock Happens-Before locks this lock in the future.
The management process is our synchronized here (as for why it is called management process, which we will introduce later), we know that the critical area modified by synchronization is mutually exclusive, that is, only one thread executes the code of the critical area at the same time; A lock unlocks Happens-Before subsequent locking of this lock "means that the unlocking operation of the previous thread is visible to the locking operation of the next thread. Based on the transitive principle of Happens-Before, we can get the previous thread Shared variables modified in the critical section (before the operation is unlocked) are visible to subsequent threads that enter the critical section (the operation is after the lock).
According to this rule, if multiple threads execute the addOne () method at the same time, visibility is guaranteed, that is, if there are 1000 threads executing the addOne () method, the final result must be that the value of value is increased by 1000. Seeing this result, we breathed a sigh of relief and the problem was finally solved.
But maybe you accidentally overlooked the get () method. After the addOne () method is executed, is the value of value visible to the get () method? This visibility cannot be guaranteed. The lock rule in the management process only guarantees the visibility of subsequent locks on this lock, and the get () method does not have a lock operation, so visibility cannot be guaranteed. How to solve it? It's very simple. Even the get () method is synchronized. The complete code is shown below.
class SafeCalc{
long value = 0L;
synchronized long get(){
return value;
}
synchronized void addOne(){
value += 1;
}
}
The above code translates into the lock model we mentioned, and it looks like this. Both the get () method and the addOne () method need access to the protected resource value, which is protected with this lock. In order for a thread to enter the critical sections of get () and addOne (), it must first obtain this lock, so that get () and addOne () are also mutually exclusive.
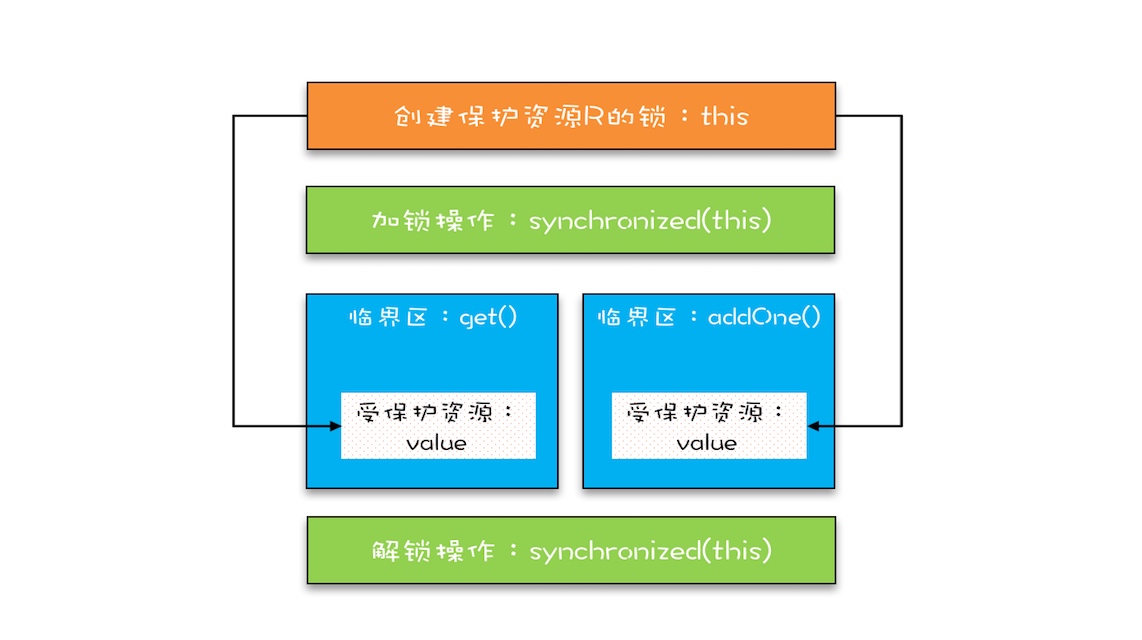
This model is more like the management of ball game tickets in the real world. One seat is only allowed for one person. This seat is a "protected resource". The entrance to the stadium is a method in the Java class, and the ticket is a "lock" used to protect resources. The ticket checking in Java is solved by synchronized.
The relationship between locks and protected resources
We mentioned earlier that the relationship between protected resources and locks is very important. What is their relationship? A reasonable relationship is: the relationship between the protected resource and the lock is N: 1. We also take the analogy of the management of the tickets for the previous game, that is, a seat. We can only use one ticket to protect it. If we issue more duplicate tickets, we will fight. In the real world, we can use multiple locks to protect the same resource, but it is not possible in the concurrent domain, and the locks in the concurrent domain and the real world locks are not exactly matched. However, it is possible to use the same lock to protect multiple resources. This corresponds to the real world is what we call a "reservation field".
I changed the above example a bit, changed value to a static variable, and changed the addOne () method to a static method. Is there a concurrency problem between the get () method and the addOne () method?
class SafeCalc{
static long value = 0L;
synchronized long get(){
return value;
}
synchronized static void addOne(){
value += 1;
}
}
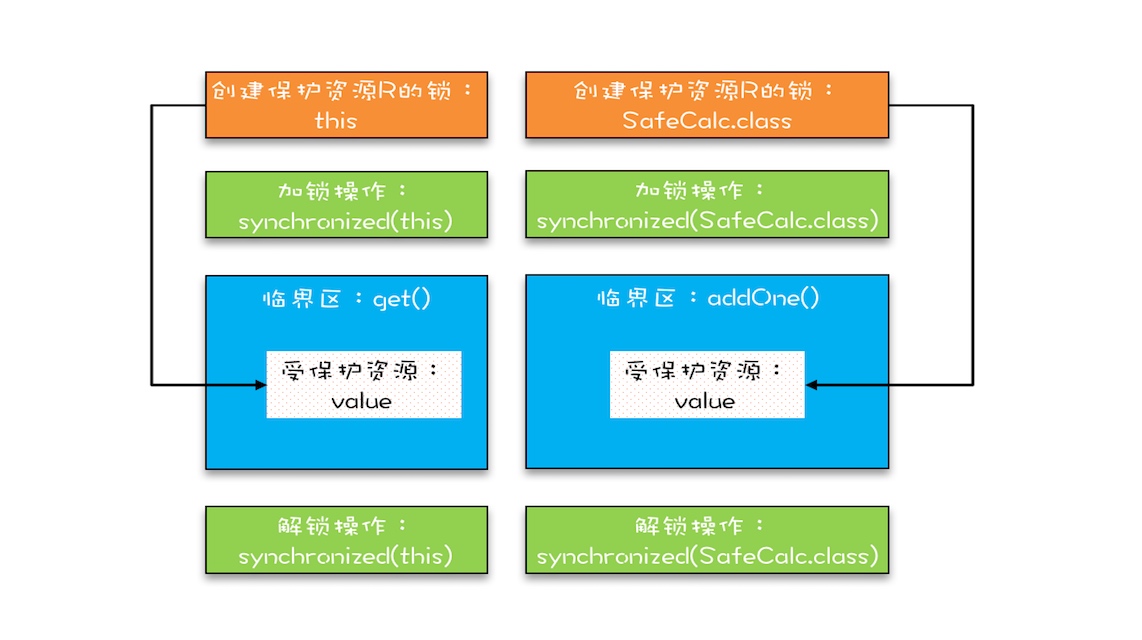
If you look closely, you will find that the changed code protects a resource with two locks. This protected resource is the static variable value, and the two locks are this and SafeCalc.class. We can use the following picture to describe this relationship. Because the critical sections get () and addOne () are protected by two locks, there is no mutual exclusion between the two critical sections. The modification of value by the critical section addOne () does not guarantee the visibility of critical section get (). This leads to concurrency issues.
Summary
Mutual exclusion locks are very well-known in the field of concurrency. As long as there is a concurrency problem, the first thing everyone thinks about is locks, because everyone knows that locks can guarantee the mutual exclusion of critical section code. Although this understanding is correct, it cannot guide you to really make good use of the mutex. The code of the critical section is the path to operate the protected resource, similar to the entrance of the stadium. The entrance must be checked for tickets, that is, locked, but not just a lock can be effective. Therefore, the relationship between the locked object and the protected resource must be analyzed in depth, and the access path of the protected resource must be comprehensively considered. Multiple considerations can be used to make good use of the mutex.
Synchronized is a mutex primitive provided by Java at the language level. In fact, there are many other types of locks in Java, but as mutual exclusion locks, the principles are the same: locks, there must be an object to be locked. The resources the object protects and where to lock / unlock are at the design level.
评论